The Salesforce Agent That Actually Works in Production
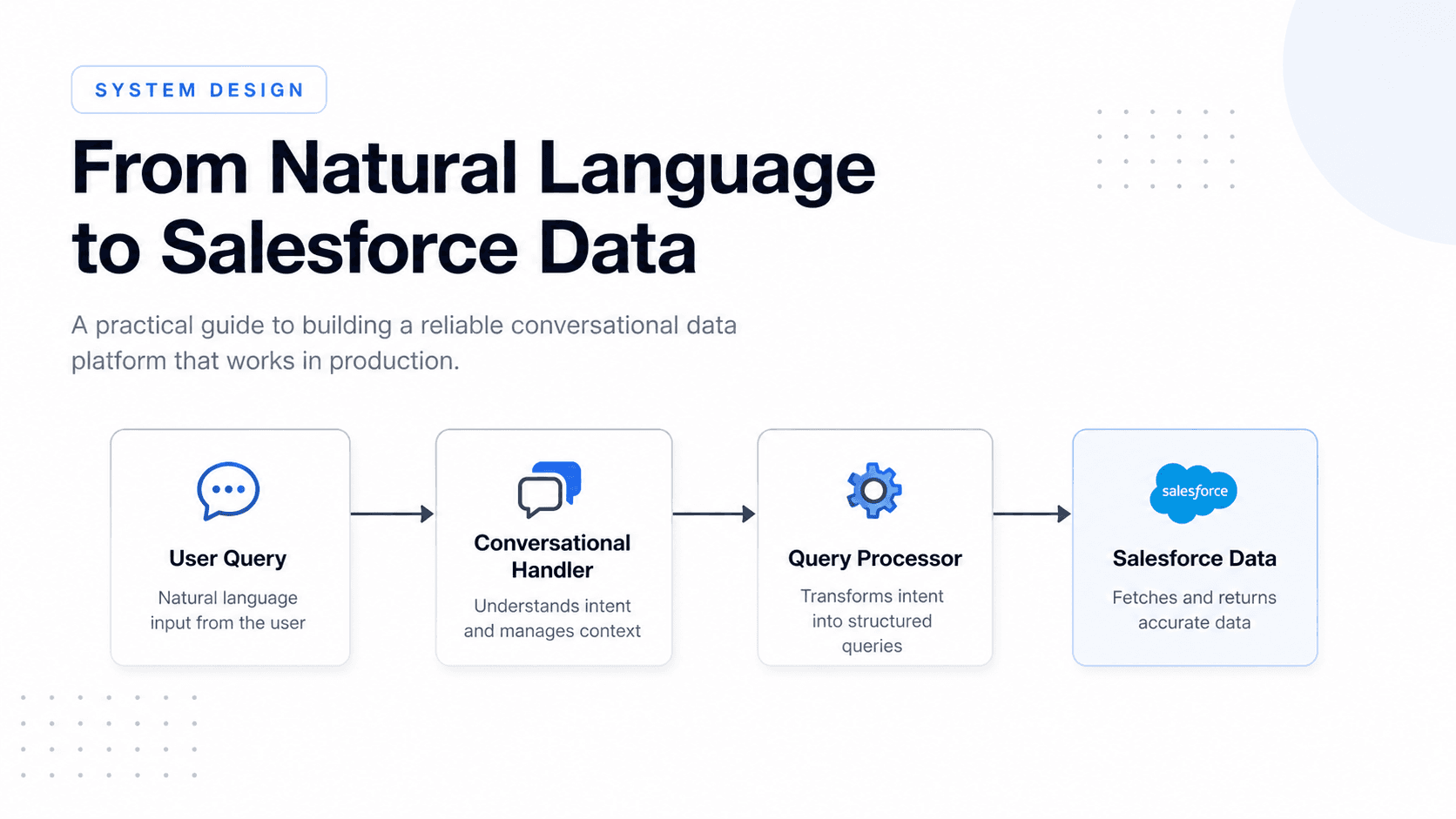

Ever wanted to have a chat with your Salesforce instance—and actually get correct, reliable data back? Converting natural language into SOQL can look simple in a demo. In production, it breaks in predictable ways. This post covers the system design decisions that made it reliable.
Why this is harder than it looks
Basic approaches fail for the same reasons every time:
Invalid field references — generated queries include fields that don't exist in the org
Wrong object assumptions — systems default to standard Salesforce objects that aren't actually used
Retry loops — without execution limits, a failing query retries until it times out
Redundant authentication — parallel queries trigger duplicate token requests under load
Cross-tenant data leakage — shared context bleeds between customers in multi-tenant deployments
A better prompt does not fix any of these. Each requires a system-level decision.
Architecture
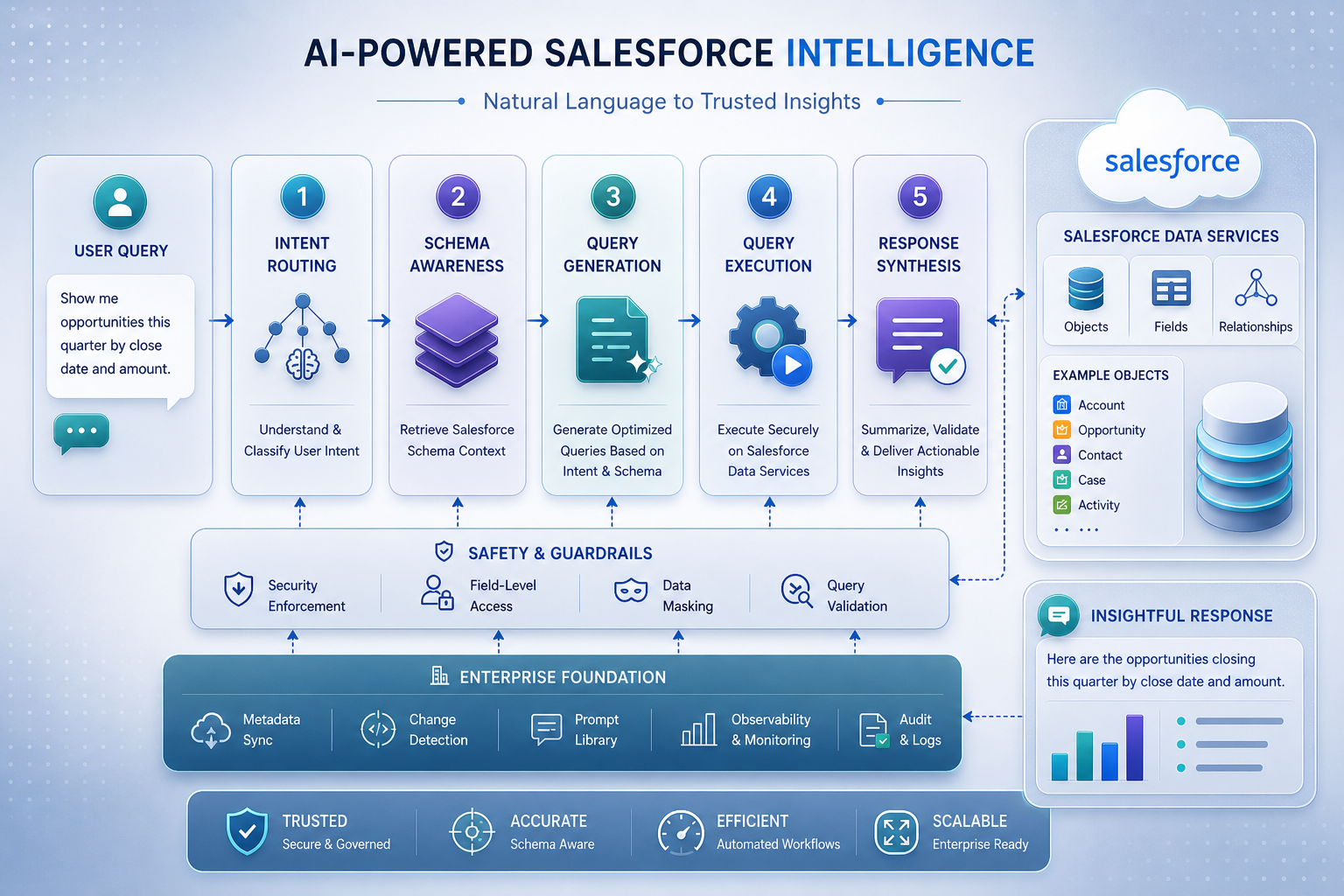
Responsibilities are split between two components: a main conversational handler and a domain-specific query processor. The handler manages interaction flow. The processor owns schema context, query generation, execution, and result formatting.
User question
→ Conversational handler
→ Salesforce query processor
├─ Schema context (loaded at startup)
├─ Query hints (similar past queries)
├─ Execution layer (single + parallel)
└─ Execution guard (call budget enforcer)
Keeping them separate means guardrails on the query processor evolve independently without touching the top-level agent.
1. Preload schema at startup
The single most impactful change: load the full Salesforce schema during connector initialization and inject it into the processor's context before the first user message arrives.
By the time a user asks a question, the system already knows every queryable object and field in that org. There are zero schema-discovery calls per question. The query is built correctly on the first attempt.
If the metadata fetch fails at startup, the system falls back to the Salesforce describe API. In practice the cached context is available nearly all of the time.
2. Cache authentication tokens with a lock
Fetching a new OAuth token on every query adds latency. Under parallel load, it creates a thundering herd — multiple coroutines requesting a fresh token at the same time even though one would be sufficient.
The solution is a token cache with an expiry buffer and a lock:
Request needs a token
→ Check cache
→ Valid → return immediately
→ Expired → acquire lock
→ Re-check cache (another request may have refreshed)
→ Fetch new token if still needed
All concurrent queries reuse the same cached token. One HTTP call per expiry cycle regardless of how many queries fire simultaneously.
3. Reuse proven query patterns

Schema context tells the system what fields exist. It does not tell it which queries actually work well on that org's data.
Every successful query is stored alongside a plain-language description of what it retrieves. On new questions, similar past queries are retrieved and injected into context as examples. The processor builds on patterns that already work rather than generating from scratch every time.
Not every query is worth storing. Trivial or exploratory queries pollute the pool. Only queries that return meaningful results with real aggregation or relationship traversal are kept.
First-attempt accuracy improves with usage as the hint pool grows.
4. Run independent queries in parallel
Multi-metric questions — "show me enrollments, fee collection, and attendance" — require several independent queries. Running them sequentially multiplies latency unnecessarily.
Independent queries run concurrently with a cap to avoid overloading the API. Total response time is roughly the slowest individual query, not the sum of all of them.
5. Enforce a hard execution limit
Without a budget, a system can retry endlessly, run duplicate queries, and return contradictory results.
A hard limit caps total operations per question. A separate tighter limit caps query executions specifically. When either limit is reached, the system returns the best result it has rather than continuing.
The limit resets at the start of each new question, not mid-turn. This ensures one coherent budget per user request regardless of how many internal steps it takes to answer.
Multi-tenant isolation
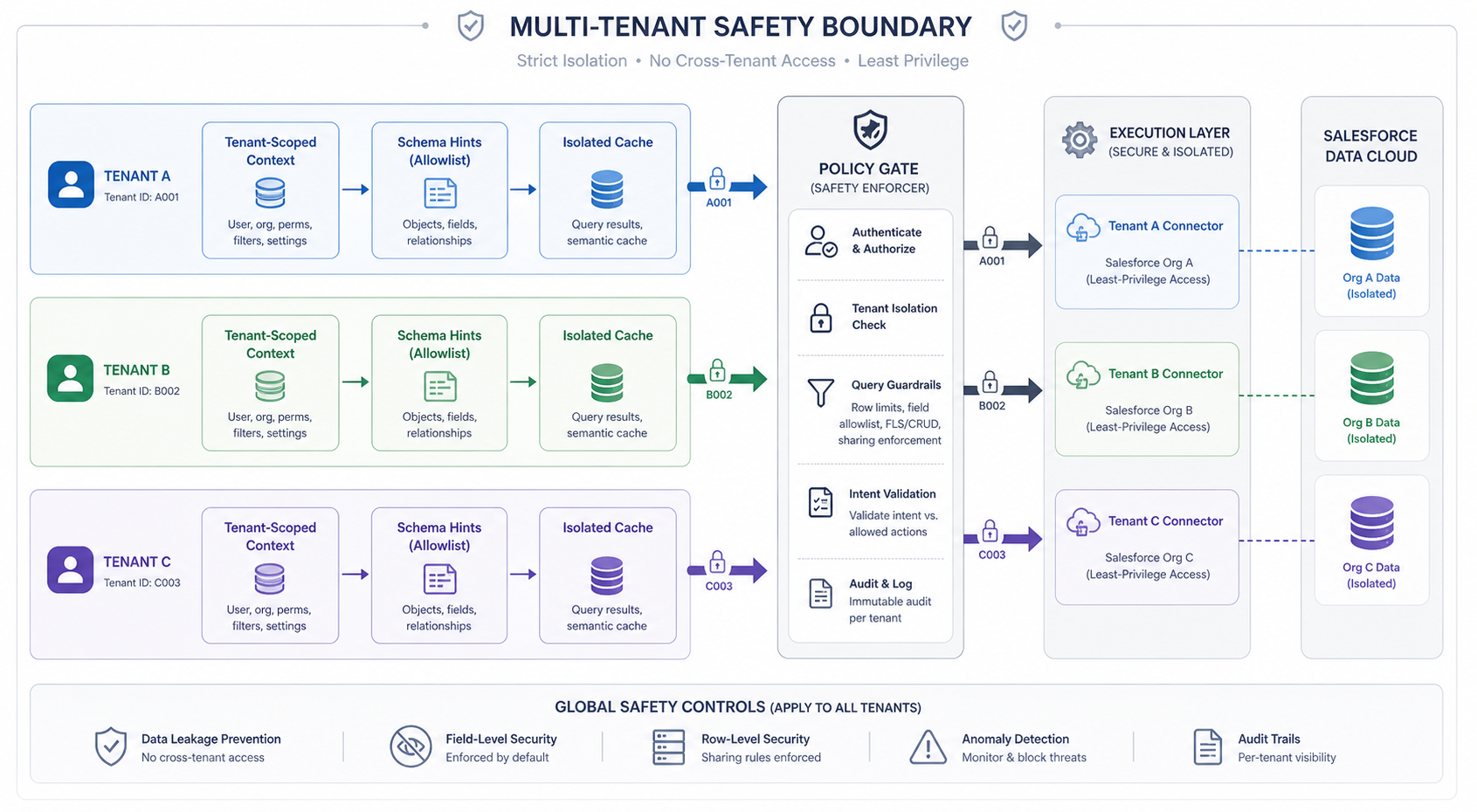
All caches — schema context, tokens, query hints — are scoped per tenant. There is no shared pool. One customer's query history and schema never influences another's.
Natural language convenience must not weaken data isolation.
What this buys you

| Without these patterns | With these patterns |
|---|---|
| Schema discovery on every question | Schema in context at startup |
| Redundant token requests under parallel load | One token fetch, shared across all concurrent queries |
| Query built from scratch every time | Proven patterns injected from history |
| Sequential multi-query responses | Parallel execution, latency ≈ slowest query |
| Retry loops until timeout | Hard limit forces synthesis from available data |
| Shared context across tenants | All caches scoped per tenant |
Takeaway
This is a systems design problem, not a prompt engineering problem.
The pieces that matter:
Schema preloaded into context — no field hallucination
Token cache with a lock — no redundant auth under load
Reusable query patterns — accuracy improves with usage
Parallel execution — multi-metric answers without serial wait
Hard execution limit — no loops, no contradictory results
Tenant-scoped caches — safe to run across many orgs
Each piece is independently motivated. Together they make the difference between something that works in a demo and something you can run in production.